

机器学习如今已经成为一种众所周知的主流创新技术,它作为人工智能的核心技术,是使计算机具有智能的根本途径。一项研究发现,人们目前使用的设备中有77%正在使用机器学习技术。
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
综合考虑各种学习方法出现的历史渊源、知识表示、推理策略、结果评估的相似性、研究人员交流的相对集中性以及应用领域等诸因素。将机器学习方法区分为六类。
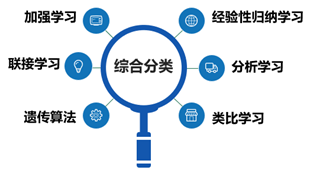
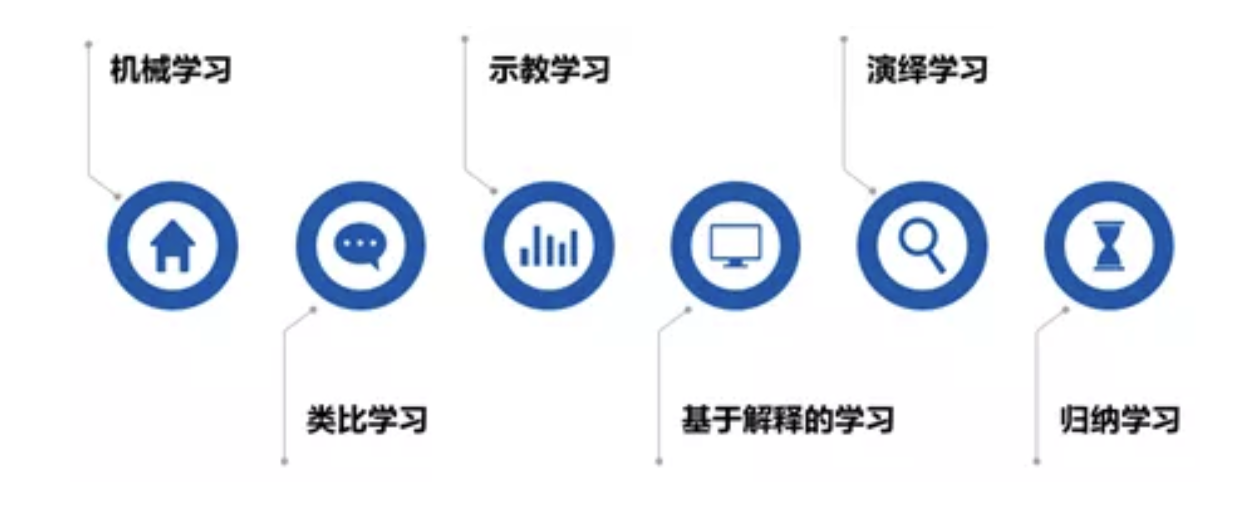
学习策略是指学习过程中系统所采用的推理策略。一个学习系统总是由学习和环境两部分组成。由环境(如书本或教师)提供信息,学习部分则实现信息转换,用能够理解的形式记忆下来,并从中获取有用的信息。学习策略的分类标准就是根据学生实现信息转换所需的推理多少和难易程度来分类的,依从简单到复杂,从少到多的次序分为以下六种基本类型:
学习系统获取的知识可能有:行为规则、物理对象的描述、问题求解策略、各种分类及其它用于任务实现的知识类型。对于学习中获取的知识,主要有以下一些表示形式:

有两种方法可以将所有的机器学习算法进行分类。分别是学习风格和通过形式或功能相似两种。通常,这两种方法都能概括全部的算法。
算法可以通过不同的方式对问题进行建模,但是,无论我们想要什么结果都需要数据。此外,算法在机器学习和人工智能中很流行。
基本上,在监督机器学习中,输入数据被称为训练数据,并且具有已知的标签或结果,例如垃圾邮件/非垃圾邮件或股票价格。在此,通过训练过程中准备模型。此外,还需要做出预测。并且在这些预测错误时予以纠正。训练过程一直持续到模型达到所需水平。
在无监督机器学习中,输入数据未标记且没有已知结果。我们必须通过推导输入数据中存在的结构来准备模型。这可能是提取一般规则,但是我们可以通过数学过程来减少冗余。
输入数据是标记和未标记示例的混合。存在期望的预测问题,但该模型必须学习组织数据以及进行预测的结构。
ML算法通常根据其功能的相似性进行分组。例如,基于树的方法以及神经网络的方法。但是,仍有算法可以轻松适应多个类别。如学习矢量量化,这是一个神经网络方法和基于实例的方法。
回归算法涉及对变量之间的关系进行建模,我们在使用模型进行的预测中产生的错误度量来改进。
该类算法是解决实例训练数据的决策问题。这些方法构建了示例数据的数据库,它需要将新数据与数据库进行比较。为了比较,我们使用相似性度量来找到最佳匹配并进行预测。出于这个原因,基于实例的方法也称为赢者通吃方法和基于记忆的学习,重点放在存储实例的表示上。
正则化算法很流行且功能强大。
决策树方法用于构建决策模型,这是基于数据属性的实际值。决策在树结构中进行分叉,直到对给定记录做出预测决定。
这些方法适用于贝叶斯定理的问题,如分类和回归。
几乎所有的聚类算法都涉及使用数据中的固有结构,这需要将数据最佳地组织成最大共性的组。
关联规则学习方法提取规则,它可以完美的解释数据中变量之间的关系。这些规则可以在大型多维数据集中被发现是非常重要的。
这些算法模型大多受到生物神经网络结构的启发。它们可以是一类模式匹配,可以被用于回归和分类问题。它拥有一个巨大的子领域,因为它拥有数百种算法和变体。
深度学习算法是人工神经网络的更新。他们更关心构建更大更复杂的神经网络。
与聚类方法一样,维数减少也是为了寻求数据的固有结构。通常,可视化维度数据是非常有用的。
算法、算力、数据是当今人工智能应用的三大要素,人工智能的发展给数据治理带来了新的机遇和挑战。一方面,数据科学研究的兴起为数据治理提供了新的研究范式,使得数据治理的视角、过程和方法都发生了显著变化;另一方面,随着组织业务的增长,海量、多源异构数据给数据管理、存储和应用提出了新的要求。
数据治理是建立数据平台或输出数据解决方案的基础,更是目前人工智能发挥作用的重要支柱。
机器学习无疑是当前数据分析领域的热点内容,机器学习已经不断地在各行各业深入应用,国家层面已经提出将数据作为重要的生产要素。因此,数据能力是考量企业发展的重要因素,那么机器学习的应用在企业数字化转型过程中有着至关重要的作用。
以上文字来源于网络,侵权立删。